澳洲大學(xué)留學(xué)生作業(yè):客戶隨機(jī)抽樣數(shù)據(jù)的組織及表格操作講解

How to organize your data
如何組織你的數(shù)據(jù)
1. Now all you need to do now is select the first 100 rows of data your table. Use your mouse and drag down to row 101 (we go to row 101 because the first row contains the column headings).
現(xiàn)在,所有你現(xiàn)在需要做的是選擇第一個(gè)100行的數(shù)據(jù)表。使用鼠標(biāo)向下拖動(dòng)到第101行(我們?nèi)サ牡?01行,因?yàn)榈谝恍邪袠?biāo)題)。
2. We are now going to copy the first 100 observations to another worksheet (Sheet 2!). Press Ctrl-C
現(xiàn)在,我們要復(fù)制到另一個(gè)工作表(表2)第100個(gè)觀測。按Ctrl-C
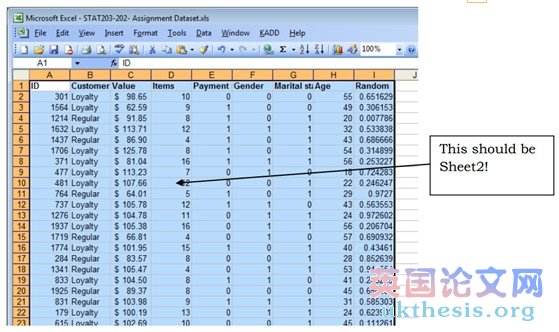
3. Now click Sheet2 (in red above), and select cell A1. Then press Ctrl-V to paste:
現(xiàn)在單擊Sheet2中(紅色以上),并選擇單元格A1。然后按Ctrl-V粘貼:

4. Now that you have your random sample of 100, you will want to split it into 2 sub-samples. As an example, let use divide our sample by Customer Type:
現(xiàn)在,你有你的隨機(jī)抽樣100,你會(huì)想它分割成2個(gè)子樣本。作為一個(gè)例子,我們使用按客戶類別劃分我們的樣本:
http://ukthesis.org/thesis_sample
a. Select a cell in the table and press Ctrl-A to select the entire sample.
選擇表中的一個(gè)單元格,然后按Ctrl-A鍵選擇整個(gè)樣本。
b. Click Data->Sort. We want to sort by Customer Type (column B).
點(diǎn)擊數(shù)據(jù)排序。我們要排序按客戶類別(B列)。
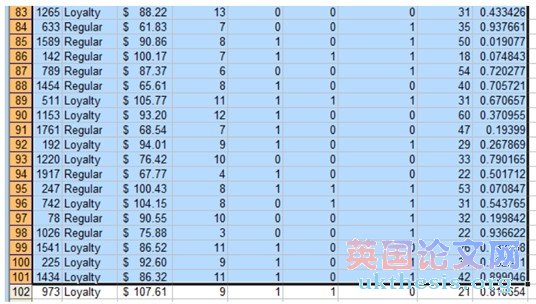
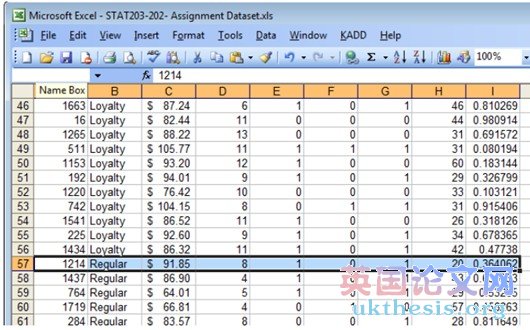
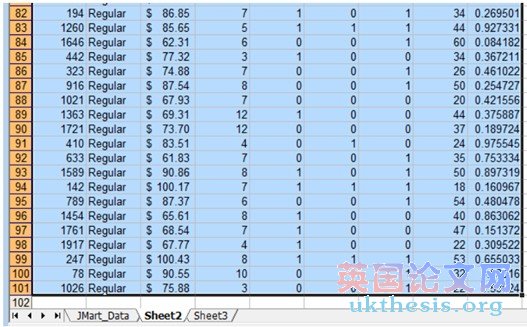
5. Now scroll down the data set and look at column B. We want to find the first row containing a „Regular? customer. In this example, we want to take all rows starting for row 57 and move them to a separate part of the spreadsheet.
現(xiàn)在,向下滾動(dòng)的數(shù)據(jù)集,并期待在B列,我們希望找到的第一行包含一個(gè)“普通”顧客。在這個(gè)例子中,我們要采取一切行57行開始,將它們移動(dòng)到一個(gè)單獨(dú)的電子表格的一部分。
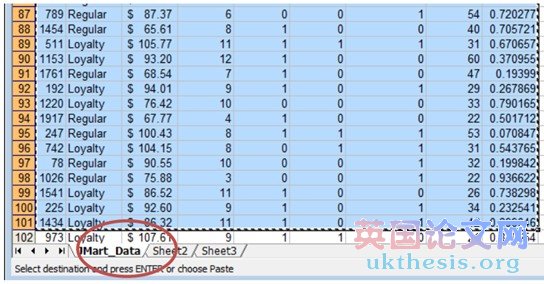
6. Use your mouse to select the first now containing a „Regular? customer. Then Ctrl-Shift-(down key ↓).
使用鼠標(biāo)選擇現(xiàn)在包含一個(gè)“普通”顧客第一。然后按Ctrl-Shift鍵(上下鍵↓)。
#p#分頁標(biāo)題#e#
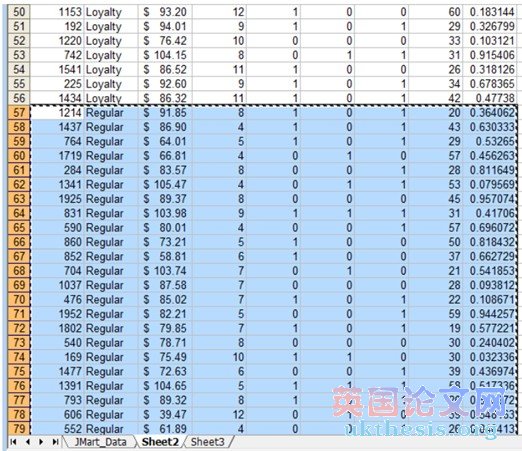
7. All observations containing „Regular? customers should be selected. Now press press Ctrl-X to „cut?.
應(yīng)選擇“常規(guī)”客戶的所有觀測。現(xiàn)在,按按Ctrl-X“剪切”。
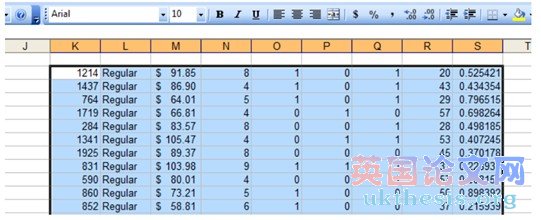
8. Now scroll up to the top of the spreadsheet. Select cell K2 and click Ctrl-V to paste:
現(xiàn)在滾動(dòng)到電子表格頂部。選擇細(xì)胞K2點(diǎn)擊Ctrl-V鍵粘貼:
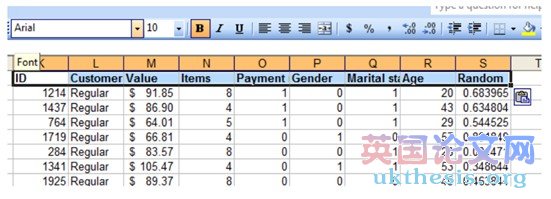
9. Now copy the headings over to the new sub-table. Select cells A1-I1, press Ctrl-C then paste at K1.
現(xiàn)在的標(biāo)題復(fù)制到新的子表。選擇單元格A1-I1,然后按Ctrl-C粘貼在K1。
Now we?ve successfully divided our sample by Customer Type! In effect, we have created 2 sub-samples, one sampling from the „Loyalty? customer population and the other from the „Regular? customer population.
“現(xiàn)在,我們已經(jīng)成功地將我們的樣本按客戶類型劃分!實(shí)際上,我們已經(jīng)創(chuàng)建了2個(gè)子樣本,一個(gè)抽樣從“忠誠”的客戶群體,并從“常規(guī)”的客戶群體。
